模型思维(2)-- 正态分布

这个图片展示了不同的平均值和方差的正态分布,这可以说是生活中最常见的模型了。很多地方都可以看到正态分布的影子,例如大多数生物的高度和重量都可以看到正态分布。那么为什么会出现正态分布呢?在什么情况下可以把分布看作正态分布呢?正态分布有什么应用?这篇文章将回答这些问题。
为什么存在正态分布
这里首先需要提到中心极限定理:
在适当的条件下,大量相互独立随机变量的均值经适当标准化后分布收敛于正态分布.
这里用抛硬币的例子来说明这个问题,每次抛硬币是独立同分布的。如果连续抛10000次硬币,每次抛硬币的正反概率都是1/2,之后计算出现正面的概率。重复做这个实验很多次,得到的正面结果的分布就是一个正态分布。
中心极限定理的特殊之处在于不管每个独立事件的分布如何,最后都是成立的。经研究发现,当 N > 20 的时候,这些独立事件的均值就服从正态分布。因为N是固定的,所以也可以看作这些独立事件的和是正态分布的。
重要的一点在于,服从正态分布的是许多随机事件的个体的均值或者是和,并不是独立的事件出现的本身。这时候聪明的读者可能就会想,那么为什么每个人的身高是符合正态分布呢?
人的身高是受到本身的基因和外界坏境影响。经过研究发现,基因的贡献率可能高达80%,所以在这里简化认为人的身高只受到基因的影响。研究发现至少180个基因有助于人的身体长高,这些基因在人类的身体里是共有的,不过表达的程度不同,所以可以把一个人的身高看作这些基因的表现之和。由此解释了为什么人的身高符合正态分布。
而对于一些事情,其实就不应该符合正态分布,例如一次考试的成绩。成绩受到试卷的难度,学生的水平多方面影响,很难看作独立同分布事件之和,所以成绩并不符合正态分布的假设。如果把很多同学成绩的均值进行统计,是符合正态分布的。而在一些地方,会强行要求每个同学的成绩符合正态分布,这无疑是一件很难的事情。大学成绩要求正态分布合理吗?
正态分布的一些应用
我们可以利用正态分布解释为什么罕见结果在规模小的群体里更加常见。随机变量均值的标准差并不等于分布的标准差/N, 同样的,随机变量的和的标准差也不是等于分布的标准差 * N。
$$\sigma_\mu=\frac{\sigma}{\sqrt{N}}$$ $$\sigma_\Sigma= \sigma \sqrt{N}$$
当群体比较大的时候,均值的波动会比较小,但是和的波动就会比较大。当群体小的时候,均值的标准差会比大群体大不少,所以出现极端情况会比较多。美国多州疫情数据显示:非洲裔等少数族裔确诊和死亡病例远高于平均值 我们也可以利用这条应用解释这个新闻。这个现象出现的原因:一方面是本身医疗条件和生活水平的差距,另一点也是受少数族裔本身的影响,其确症和死亡率比大群体 – 白人是要高一点。
另一个应用是六西格玛方法,它是由摩托罗拉公司于1980年代提出的,可以利用正态分布来为质量控制提供有效信息。
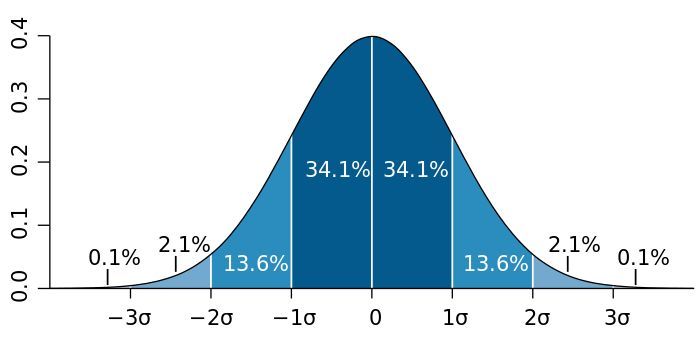
六西格玛的由来可以看这个图,$\pm 3 \sigma$ 可以包含 接近99.8%的结果。摩托罗拉公司在生产零件的时候要求产品如果出现和均值相比超过2个标准差的误差,那么就是不合格的。两个标准差之外出现的概率大概是5%,对于企业还是太高了。所以通过这种方法可以降低标准差,降低不合格产品的可能性。这里的核心思想就是在六个标准差内可以包含几乎所有的事情。
对数正态分布
如果事件是互相影响的,那么则不能用普通的正态分布来研究,而要使用对数正态分布。对数正态缺乏对称性,当大于1时,其乘积增长很快,所以会出现长尾效应。当将20个不均匀分布在0到10之间的随机变量相乘,总会出现一些很小的和一些很大的。
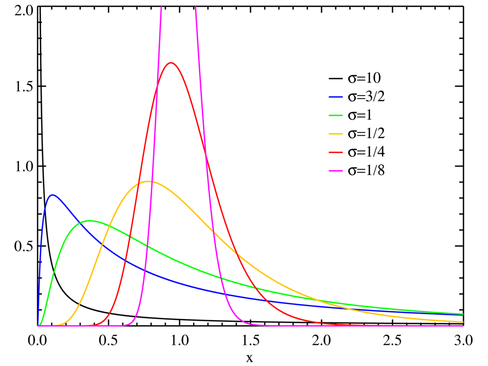
人们的工资分布可以用对数分布来解释。在不少公司里,人们是通过百分比加薪的,而不是每次增加固定的薪水。所以人的收入是多次加薪相乘的结果,而不是累加。如果每次都增加一定的薪水,则对于同一工作年限的人来说,其收入更加接近普通的正态分布。
小结
这里我们一起探讨了正态分布的由来和一些应用。正态分布之所以常见是因为中心极限定理的强大,如果一个群体里每个个体是独立的随机事件,群体的均值或者和总是可以看成其符合某种正态分布,对数正态分布则解释了当个体是互动影响的情况。